A korpusz ablakban a megnyitott korpusz szövegeire vonatkozó adatok találhatóak. Az információk egy táblázaban vannak elrendezve: minden sorban egy adott szövegre vonatkozó adatok vannak megjelenítve, és minden oszlop más és más jellemzőket tartalmaz.
Az alábbi példában a Magyar Nemzeti Szövegtár egy részkorpusza látható:
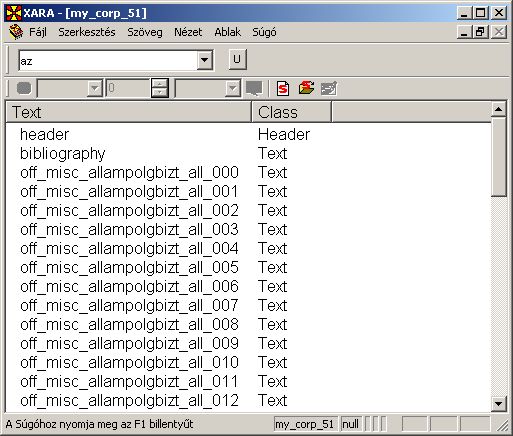
Az első két oszlop megjelenítése kötelező. Az első oszlopban a szövegek nevei találhatóak.
A második oszlop a hozzárendelt osztályok neveit tartalmazza. Az osztályokra vonatkozó további információkért olvassa el a Felosztások létrehozása oldalt. A fenti példa az alapértelmezett felosztást mutatja, ahol az összes szöveg egy osztályhoz, a "Text" (Szöveg) nevű osztályhoz tartozik.
Egy új felosztás létrehozása és aktiválása után, a "Class" (Osztály) oszlopban minden egyes szövegre megjelenik, hogy melyik osztályba tartozik.
Az alábbi példában feltettük, hogy a korpuszunkban található szövegek újságcikkek, amelyek csoportosíthatóak aszerint, hogy melyik nap (tegnap vagy ma) jelentek meg.
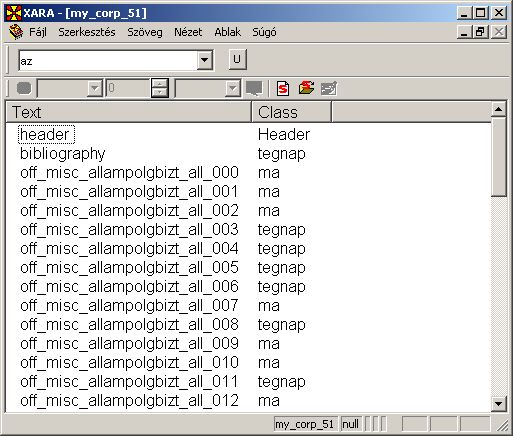
Az Oszlop megjelenítés paranccsal további oszlopok is megjeleníthetőek a korpusz ablakban. Ezek a korpuszban található XML jelölő elemeken alapulnak.
A Xaira minden egyes megnyitott lekérdezéshez automatikusan létre hoz egy oszlopot. Ez az oszlop azt tartalmazza, hogy az adott lekérdezéshez szövegenként hány találat tartozik. Például egy olyan lekérdezés megnyitása után, amelyben a "határozatlan" előfordulásaira voltunk kíváncsiak, a fenti példakorpusz megjelenítése az alábbiak szerint módosul:
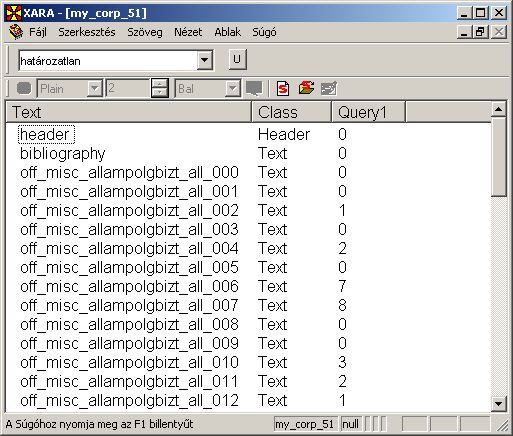
Láthatjuk, hogy az off_misc_allampolgbizt_006 nevet viselő szövegben a "határozatlan" szó hétszer fordul elő, míg az off_misc_allampolgbizt_005-ben egyszer sem.
Az oszlopok tetején található fejcímkék segítségével a szövegek listája többféleképpen is rendezhető. Ha a szövegek neveit kívánjuk ABC szerint rendezni, kattintsunk a "Text" feliratot viselő fejcímkére. Hasonlóképpen, ha a "QueryX" (ahol X az adott lekérdezés sorszáma) fejcímkéjű oszlop fejcímkéjére kattintunk, a szövegeket a bennük előforduló találatok száma szerint rendezzük.
Ha még egyszer rákattint az adott gombra, a rendezési sorrend megfordul: ha eddig csökkenő rendezés volt, ezentúl növekvő lesz, vagy fordítva.
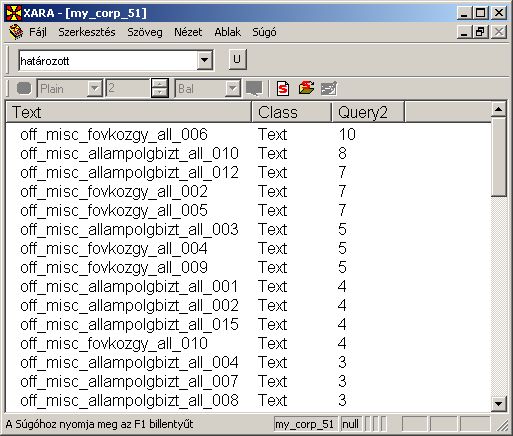
Az alábbi példában a "Query2" oszlop szerint rendeztük a szövegeket. Ez azt jelenti, hogy azok a szövegek, amelyekben több találat van, az oszlop tetején, míg azok, amelyekben kevesebb találat fordul elő, az oszlop alján helyezkednek el.
Ha ki akar jelölni egy szöveget, kattintson a szöveg nevére a baloldai oszlopban. A kiválasztást a kurzor billenyűkkel változtathatja meg. Ha egyszerre több szöveget kíván kijelölni, tartsa lenyomva a CTRL billentyűt, amíg rákattint a megfelelő szövegekre. Ha szomszédos szövegeket szeretne kijelölni, nyomja le a SHIFT billentyűt és kattintson az Ön által kiválasztott legutolsó szövegre.
A kijelölt szövegen a Szöveg menü parancsainak segítségével a következő műveleteket hajthatja végre: hozzárendelheti egy osztályhoz, megtekintheti a szöveg bibliográfiai adatait vagy böngészhet benne.
Ezek a parancsok szintén megtalálhatók a korpusz ablak helyzetérzékeny menüjében, melyet úgy jeleníthet meg, hogy jobb-egérrel a megfelelő szövegre kattint:

A menü felső részén található parancsok megegyeznek a Szöveg menü Böngészés és a Forrás parancsaival. A menüt kettészelő vízszintes vonal alatt a jelenleg aktív felosztás osztályai láthatóak (ld. még fenn). A példában a megfelelő osztályok a "tegnap" illetve a "ma". Ha a kiválasztott szöveget az osztályok valamelyikéhez kívánja rendelni, kattintson a megfelelő osztályra a helyzetérzékeny menüben.